PHISH.NET SHOW RATINGS, PART 2: FLUFFERS, BOMBERS, AND OTHER ANOMALOUS RATERS
[We would like to thank Paul Jakus (@paulj) of the Dept. of Applied Economics at Utah State University for this summary of research presented at the 2024 Phish Studies Conference. -Ed.]
Numerous Phish.Net Forum threads have hypothesized about the effect of people with extreme ratings behavior on show ratings, so this post will focus on the behavior of (anonymous) individual raters. The most well-known of extreme raters are “bombers”, or those who rate all shows as a ‘1’. “Fluffers”—those who rate every show a ‘5’—have received less attention than bombers.
The ratings database has 88 people who qualify as pure bombers and, adding them all up, this group has submitted a total of only 268 ratings out of 343,241 total ratings (0.08%). The database contains 5,499 pure fluffers, or people who have rated shows using only ‘5’. Clearly, fluffers are far more prevalent in the data, and account for 15,757 of all show ratings (4.59%).
But that’s not all. Remember Rater B from the first post in this series, with those 947 performances rated as ‘5’ and one show as a ‘4’? They’re not a pure fluffer, so if we are concerned about extreme rating behavior we must look beyond pure bombers and fluffers. Further, the terms “bomber” and “fluffer” imply deliberate manipulation of ratings. We simply cannot know if a submitted rating is designed to manipulate, or if it reflects true beliefs. Thus, the product marketing literature refers to these people as “anomalous” raters, and has developed a number of statistics designed to reveal them in large databases. We’ll look at how two of these measures—average deviation and entropy—work with the ratings database.
Consider the ratings profiles of several real (but anonymous) raters pulled from the database. Raters A and B first appeared in the first blogpost (A gave the most ‘1s’ whereas B gave the most ‘5s’). Rater C is a pure fluffer (all ‘5s’) and Rater D (all ‘1s’) is a pure bomber. Raters E and F are broadly representative of the typical user in the database—a lot of ‘5s’, and a few ‘4s’ and maybe a couple of ‘3s’. Rater G tends to use either a ‘5’ or a ‘1’, and only rarely uses ratings in between (i.e., a simple “thumbs up/down” scale.)
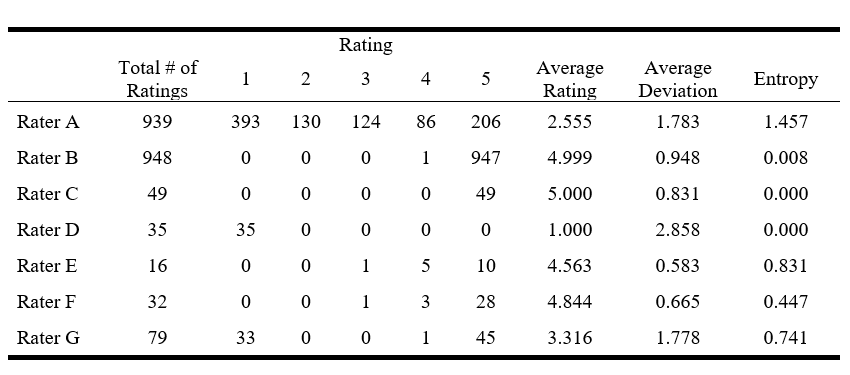
Average Deviation. This measures the average difference between a person’s show rating and the mean show rating of all raters, for all shows a person has rated. In our ratings database, large average deviations can occur only when a person uses a lot of ‘1s’ relative to their other ratings. Rater D, a pure bomber over 35 shows, has a large average deviation (2.858). Raters A and G have lower average deviations (despite a lot of ‘1s’) because of their ‘4s’ and ‘5s’.
Entropy. Entropy measures the average expected value of information provided by a rater. The formula for entropy can be found [here, Wikipedia link below]. Smaller values of entropy are associated with less informational value, and the intuition is straightforward: Look at Rater C and make your best guess as to what their next show rating will be? If C provides anything other than a ‘5’, we’d be surprised. Similarly, what do you think the next rating from Rater D will be? Again, anything other than a ‘1’ would be a surprise.
The expected average value of information (entropy) is zero for both pure fluffers (Rater C) and pure bombers (Rater D). From an informational perspective, fluffers and bombers are identical, and the motivation for their response (honest or manipulative) is irrelevant. We can predict perfectly what their next rating will be, regardless of the quality of Phish’s next performance, so they are of no help in assessing show quality.
Entropy suggests the expected informational value of Rater B’s next rating is a very low (0.008) because they are almost always a ‘5’. In contrast, Rater A uses the full scale, and so has a very high entropy score: there’s likely a lot of informational value in their rating. The same holds true for Raters E, F and G.
Part 3 of this series will address issues of statistical bias in the database, and how anomalous raters (identified by average deviation and entropy) may contribute to that bias.
WIKI LINK: https://en.wikipedia.org/wiki/Entropy_(information_theory)
Comments
You must be logged in to post a comment.
 The Mockingbird Foundation
The Mockingbird Foundation
I don't know how much access you have to the ratings data, but would be fun to take a look at the entropy distribution and select an entropy threshold to filter the ratings and derive a "high-information" rating for each show. Nothing quite as fun as nerdery (to this particular nerd), other than, of course, a Phish show.
This would be true if C and D rated literally every show. But they don't. I'm obviously just speculating, but my guess is that Rater C only rates shows they think are under-rated, and D only rates shows they think are over-rated. If I'm right, their votes could actually help assess show quality.
Note that I am not condoning such rating behavior. I think people should rate a broad swath of shows and give their honest assessment, independent of what the current show avg-rating is. I'm just pointing out that the entropy concept is potentially misleading in this context. Ratings are complicated!
Another possibility is that Rater C is so selective about the shows they rate, that they only rate those that we all agree are the "best." This is not so much a response bias as a sampling bias (see tomorrow's blogpost.) Again, how much does it really help if Rater C looks for highly rated shows, listens to those shows, and then rates them highly? Or if they choose to rate only those shows they view as worthy of a '5'?
Again, the beauty of the entropy measure is that one does not need to speculate why someone's ratings follow a given pattern.
But let's come at it from a different perspective. Let's assume that Rater C will submit a show rating for the first night of Dick's 2024. Let's further assume that we agree to bet $100 today, almost a full week before the show happens, on what Rater C will submit. My $100 says that C will submit a '5', and your $100 says it will not be a '5'. Would you take that bet?
I suspect that most folks would not take that bet because, regardless of what happens Dick's 2024 N1, Rater C is gonna come in with a '5'. The measure of entropy, the expected average value of information, is zero because they are perfectly predictable.
My anonymized database doesn't have personal information; I don't have any of the verification info, and everyone's .Net handle was converted to a randomized 32-digit alphanumeric User ID. This ID allowed me to track any one person's rating history over time, but nothing else.